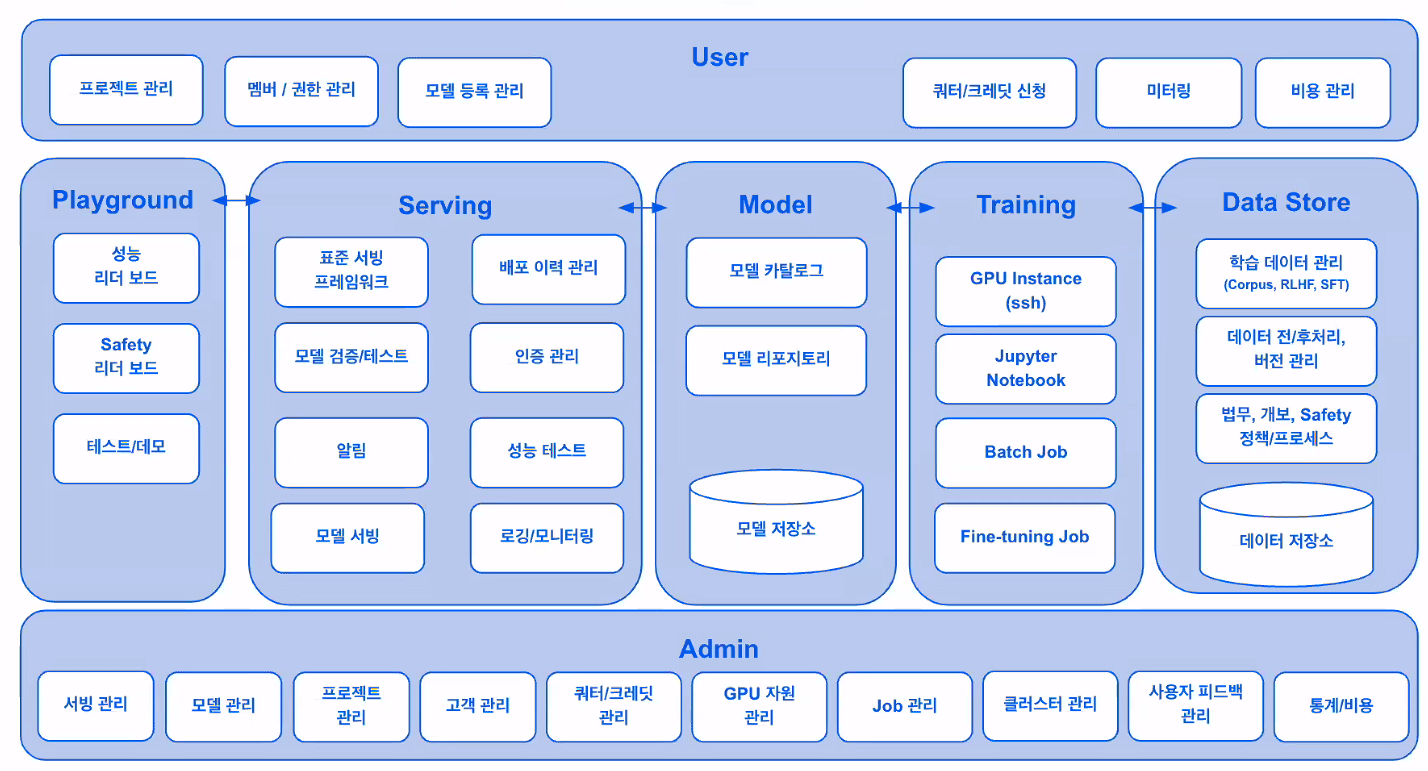
Kakao AI Platform(KAP)

ex. speculative decoding
: 큰 모델과 작은 모델 같이 띄워서 작은 모델로 추론 (높은 속도, 낮은 정확성)
-> 추론한 토큰 여러개 grouping해 큰모델한테 전달 -> 확률 분포 값 계산 -> 토큰 유효성 판단
KAP Serve / Training
1) Inference 기능
- AI Model 카탈로그 : 다양한 AI 모델 접근 가능
- 모델 & GPU 선택: 사용자 맞춤형 Inference API Endpoint 생성
- 통합 관리 : 인증, 보안, 성능, 로깅 모니터링
ex. 카카오톡 AI 요약/어조 변경 가능
2) Training / Fine-Tuning 기능
- 모델 & 데이터 선택, 파인튜닝, 결과 자동 평가, 서비스 배포
- 작업 큐 & 스케줄러: 배치 잡, 장기/병렬 잡, Interactive console UI
- 효율적 작업 관리: 쿼터/크레딧 기반 작업 처리
KAP Data Store
[데이터 유형]
1) Corpus (그냥 아무데서나 긁어온 데이터)
- 모델 처음 만들 때 pretraining할 때 활용(초기학습) 단어들간의 관계 어느정도 이해함
2) SFT Data (Supervised Fine-Tuning Data)
- 지도 학습을 위한 데이터
3) RLHF Data (Reinforcement Learning from Human Feedback Data)
- 인간의 피드백을 통해 강화 학습 방식으로 AI 모델 개선을 위해 사용됨

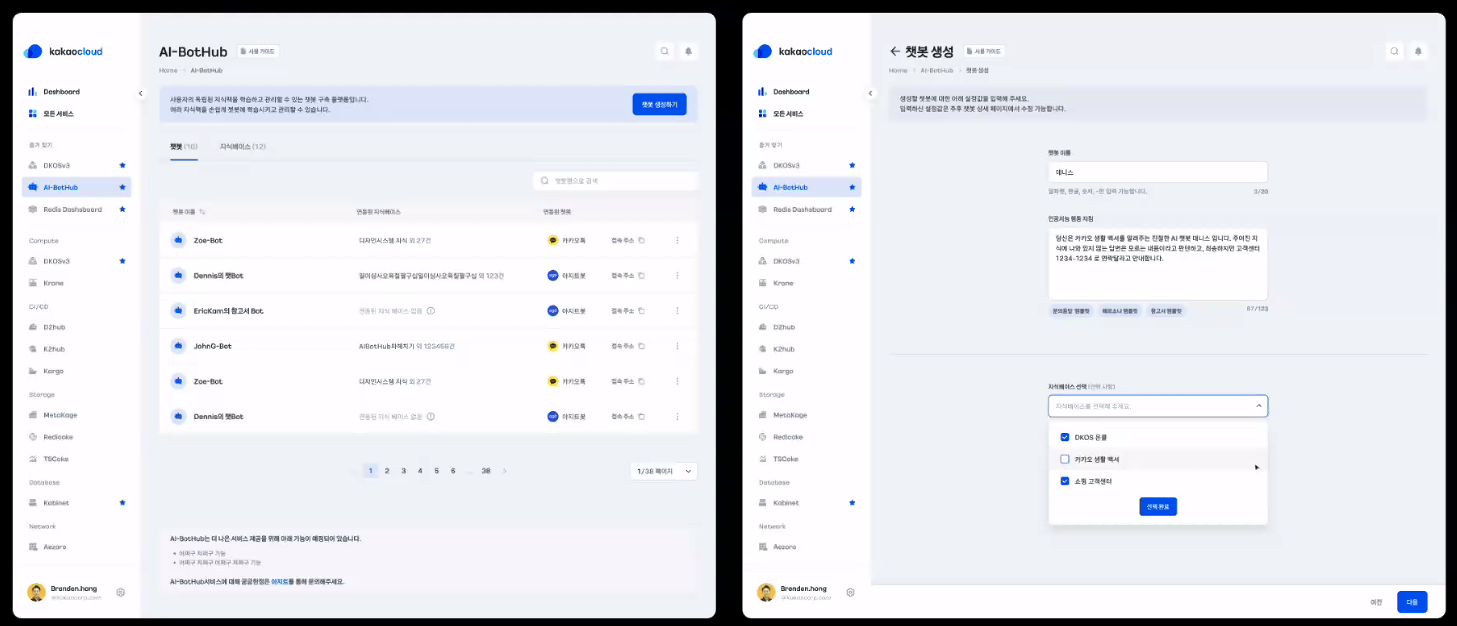
KAP Agent
코딩을 몰라도 인공지능 행동 지침(Prompt)과 +@지식학습 통해 누구나 AI 지식 챗봇 생성 가능!
생성형 AI 성숙도 모델

프로그램의 입력과 출력 관계를 결정하는 것
1. software 1.0 : algorithm
- 알고리즘 개발 통해 입력과 출력 관계 결정
- input data -> program(algorithm) -> output
단점! 케이스가 너무 많거나 애매한 것들은 소프트웨어로 풀 수 없다는 단점 발생
2. software 2.0: 데이터셋으로부터 학습된 머신러닝 모델
- 학습용 데이터 -> 데이터셋 학습 -> 머신러닝 모델
- input data -> program(ML model) -> output
단점! 학습에 많은 비용 소모, 기능별 모델 필요, 입력&출력 관계 보장X
3. software 3.0: prompt
- 프롬프트= context + 지시
- 프롬프트 일부인 컨텍스트를 프로그램으로 볼 수 있음
- 프롬프트(프로그램 + Input data) -> LLM(Agent) -> output
단점! 높은 운영 비용, 의도한 출력이 나오지 않을 가능성 존재 -> 인공지능 개발자가 가져야 할 역량
'인공지능과정 이론 수업' 카테고리의 다른 글
| AI편(2){Hello AI world;} (0) | 2024.08.12 |
|---|---|
| Day20 생성형AI IV /Llama, Finetuning, Distillation, Quantization, LoRA and QLoRA, Serving (0) | 2024.07.30 |
| Day 19 생성형AI III / LLM, ChatGPT, RAG, Langchain, LlamaIndex (0) | 2024.07.29 |
| Day18_생성형AI 프롬프트 엔지니어링 (0) | 2024.07.26 |
| Day17_생성형AI I (+Attention is All You Need) (2) | 2024.07.25 |



